実行計画の取得方法
Cloud Spanner で実行計画を取得するには、大きく分けてクエリを実行せずに実行計画だけ取得する方法と、クエリを実行して実行計画と合わせて実行統計(execution statistics)を取得する方法の2種類がある。 ここでは各 UI における取得方法を説明する。
Web UI
公式の Google Cloud Console 上から簡易的に実行計画を確認することができる。
参考
- https://cloud.google.com/spanner/docs/sql-best-practices?hl=en#how-execute-queries
- https://cloud.google.com/spanner/docs/troubleshooting-performance-regressions?hl=en#find-index
実行計画の取得方法
クエリを実行せずに実行計画を取得するには、 Run query ボタンの横のメニューから Explanation only を選択する。
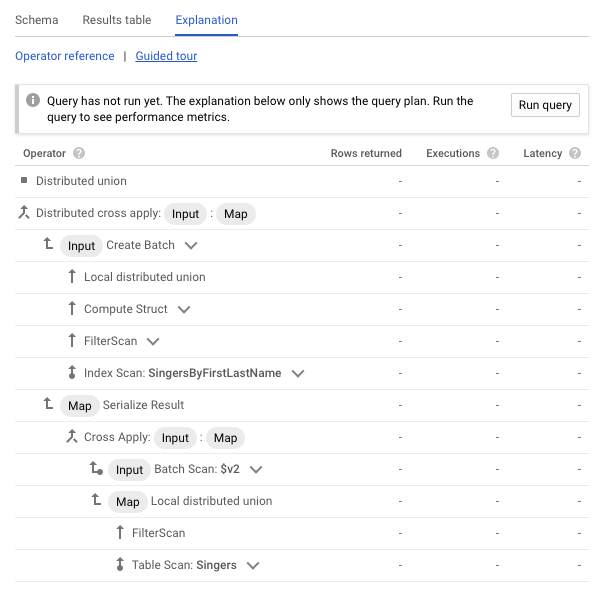
結果はツリー構造として表示されるが、どのフィルタがどのように処理されるかなどの情報は表示されない。
実行統計の取得方法
Run query ボタンを押してクエリを実行するとクエリ結果が表示されるが、 Explanation を選択することでクエリ全体および実行計画の各 operator に対応した実行統計を表示できる。
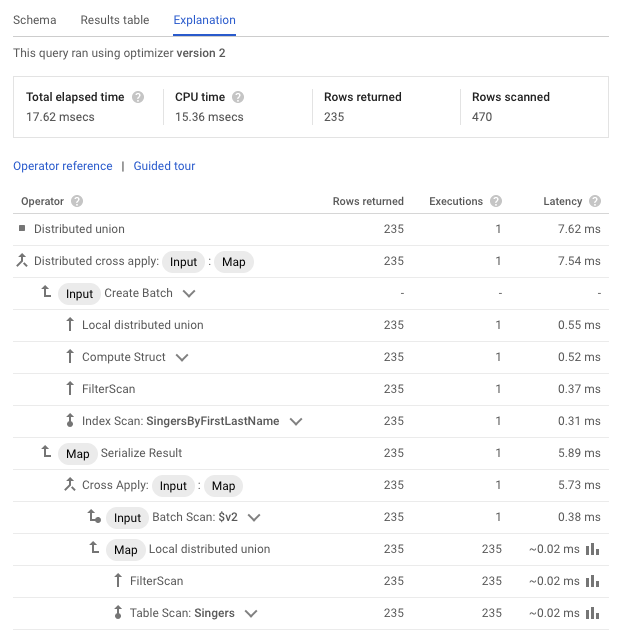
注意すべき事項として、結果の行が多すぎる場合は下記のように表示されて実行統計は取得できなくなる。
Metrics are not available for this explanation. The query returned too much data to load in the console, so the total number of rows returns, executions, and latency could not be determined.
これは、Web UI はクエリを ExecuteStreamingSQL API を使って実行するが、結果の行が多い場合はクエリの実行が分割されるため、結果を最後まで取得しない Web UI では実行統計が取得できなくなってしまうためである。 大量の結果が得られるクエリの実行統計を取得する場合は後述する spanner-cli などを使用する。
spanner-cli
実行計画の取得方法
spanner-cli を使って実行計画を取得するには、クエリの前に EXPLAIN を付けて実行する。
$ spanner-cli -p ${PROJECT_ID} -i ${INSTANCE_ID} -d ${DATABASE_ID}
> EXPLAIN SELECT * FROM Singers@{FORCE_INDEX=SingersByFirstLastName} WHERE FirstName LIKE 'A%' AND SingerId BETWEEN 10000000 AND 19999999;
+-----+--------------------------------------------------------------+
| ID | Query_Execution_Plan (EXPERIMENTAL) |
+-----+--------------------------------------------------------------+
| *0 | Distributed Union |
| *1 | +- Distributed Cross Apply |
| 2 | +- [Input] Create Batch |
| 3 | | +- Local Distributed Union |
| 4 | | +- Compute Struct |
| *5 | | +- FilterScan |
| 6 | | +- Index Scan (Index: SingersByFirstLastName) |
| 26 | +- [Map] Serialize Result |
| 27 | +- Cross Apply |
| 28 | +- [Input] Batch Scan (Batch: $v2) |
| 32 | +- [Map] Local Distributed Union |
| *33 | +- FilterScan |
| 34 | +- Table Scan (Table: Singers) |
+-----+--------------------------------------------------------------+
Predicates(identified by ID):
0: Split Range: (($SingerId >= 10000000) AND ($SingerId <= 19999999) AND STARTS_WITH($FirstName, 'A'))
1: Split Range: ($SingerId' = $SingerId)
5: Seek Condition: STARTS_WITH($FirstName, 'A')
Residual Condition: (($SingerId >= 10000000) AND ($SingerId <= 19999999))
33: Seek Condition: ($SingerId' = $batched_SingerId)
1 rows in set (0.02 sec)
ツリーの各行に対応する ID に対して、 * が表示されているものは対応する述語が Predicates の欄に列挙されているため、それぞれのフィルタがどのように処理するのかを確認できる。
実行統計の取得方法
実行統計はクエリの前に EXPLAIN ANALYZE を付けて実行することで取得できる。
> EXPLAIN ANALYZE SELECT * FROM Songs;
+----+-----------------------------------------------------+---------------+------------+---------------+
| ID | Query_Execution_Plan | Rows_Returned | Executions | Total_Latency |
+----+-----------------------------------------------------+---------------+------------+---------------+
| 0 | Distributed Union | 1024000 | 1 | 728.81 msecs |
| 1 | +- Local Distributed Union | 1024000 | 2 | 811.02 msecs |
| 2 | +- Serialize Result | 1024000 | 2 | 786.12 msecs |
| 3 | +- Table Scan (Full scan: true, Table: Songs) | 1024000 | 2 | 562.75 msecs |
+----+-----------------------------------------------------+---------------+------------+---------------+
1024000 rows in set (2.23 secs)
timestamp: 2020-09-23T04:03:43.415211+09:00
cpu: 1.94 secs
scanned: 1024000 rows
optimizer: 2
上記の例のように大量の結果を得るようなクエリであっても最後まで結果を読み捨てることで実行統計を取得し表示する。
実行計画の生データと spannerplanviz
実行計画および実行統計に含まれる全ての情報を得るには、 API 呼び出し時に得られる ResultSetStats を取得する必要がある。
API を直接呼ぶことや、 クライアントライブラリを使うなどの方法があるが、 gcloud spanner databases execute-sql に --query-mode を指定することで GCP 公式のツールを使って生の実行計画を取得することができる。
なお、デフォルトの出力は人間にもプログラムにも扱いづらいので必要に応じて --format=json か --format=yaml を指定すると良い。
実行統計の取得方法
--query-mode=PLAN を渡すと、クエリを実行せずに実行計画を ResultSet 形式で取得できる。
$ gcloud spanner databases execute-sql --project=${PROJECT_ID} --instance=${INSTANCE_ID} ${DATABASE_ID} --query-mode=PLAN --format=yaml --sql "SELECT * FROM Albums" > plan.yaml
なお SQL ファイルを指定するオプションはないため、ファイルに保存されたクエリを対象にする場合は下記のようにする必要がある。
$ gcloud spanner databases execute-sql --project=${PROJECT_ID} --instance=${INSTANCE_ID} ${DATABASE_ID} --query-mode=PLAN --format=yaml --sql "$(cat query.sql)" > plan.yaml
実行統計の取得方法
--query-mode=PROFILE を渡すと、実行計画と実行統計を含んだクエリの実行結果を ResultSet 形式で取得できる。
$ gcloud spanner databases execute-sql --project=${PROJECT_ID} --instance=${INSTANCE_ID} ${DATABASE_ID} --query-mode=PROFILE --format=yaml --sql "$(cat query.sql)" > profile.yaml
出力にはクエリの結果も含まれるため、保存するには結果が多すぎるまたは個人情報が含まれるなどクエリ結果を残したくない場合は、結果を含む rows を jq 等で削除すると良い。
$ gcloud spanner databases execute-sql --project=${PROJECT_ID} --instance=${INSTANCE_ID} ${DATABASE_ID} --query-mode=PROFILE --format=json --sql "$(cat query.sql)" | jq 'del(.rows)' > profile_reducted.json
生データの扱い方
保存した生データは別途プログラムで解析、可視化などに利用できる。 OSS としては SVG として可視化する apstndb/spannerplanviz がある。